
他可以在我的電腦裡作業!(公司SQL資料庫不能回家用QQ)
到底到底,Python Pandas有哪些實用功能? 大家都說資料分析的基本功是篩選,Python裡資料篩選功能又與SQL語言有哪些異同? 讓我們繼續看下去吧。
Pandas裡的Series, Data Frame, Panel各代表甚麼意義?
想像我今天想要用販賣機點飲料,這三種資料模式各代表的是飲料陳列的不同方式:
1. Series
[可口可樂,芬達,汽水,健怡,柳橙汁]
Series呈現方式就會是單維的資料型態,當我要點選芬達時,我只要告訴販賣機: 「我要第2個!」,販賣機自動會跳出芬達的資訊給我。
2. Data Frame
可樂1,可樂2,可樂3,可樂4,可樂5
芬達1,芬達2,芬達3,芬達4,芬達5
汽水1,汽水2,汽水3,汽水4,汽水5
健怡1,健怡2,健怡3,健怡4,健怡5
柳橙汁1,柳橙汁2,柳橙汁3,柳橙汁4,柳橙汁5
Data Frame呈現的方式會是n*n的資料類型,其實就是我們平常所看的excel報表感覺,當我要點芬達4是,我需要告訴python: 「我要第2排往左數來第4個」,因為資料已經是二維,所以給的資訊就必須更多了。
3.Panel
Series是單維,Data-Frame二維,而Panel則是三維資料了,同樣用飲料機的例子想像,Panel的資料就像是在上面例子中,每台飲料機擺放飲料是5*5瓶,而現在有4台飲料機,總共得擺5*5*4=100瓶飲料! 這時候我要叫飲料的步驟就變成: 「我要第3台飲料機裡面第2排往左數來第4個!」,這次要給的資料可說是巨細靡遺。
因為Data-Frame為比較常用的資料集方式,所以下面的語法分享比較也以Data-Frame為主喔!
Data-Frame如何預覽&選取資料?
資料分析一開始,不管是要檢查也好,想看一下樣態也好,最基本的就屬怎麼把資料「叫」出來了。
(1)匯入&預覽資料
import pandas之後,將excel原始資料用read_csv匯入,假設現在取名為nba。
當下了nba.head(3),代表我想要看到這個nba資料集的前三行,大概預覽一下資料有沒有狀況。

(2)選取1~多個欄位
假設我現在只想看一下Age&Position&Number這三個欄位,該怎麼做呢!?
用nba["Age"]可以選取1個欄位,但若多個欄位就必須再外加一個括弧[]=> nba[[想選的多欄位]]。這裡的選取等同SQL語法:「 select age, position, number from nba」,效率上也沒有差太多。

單一資料篩選&多重資料篩選
看一下覺得資料沒太大問題,就要開始篩選這次分析所需要的條件。
(1)單一條件篩選
假設我現在想要看隊名都是Boston Celtics的資料該怎麼篩選呢?
 先用nba["Team"]選等於Boston Celtics,此時會出現一連串的True/False,代表資料是Boston Celtics就會顯示True,反之則False。這邊還沒篩選到資料,只有先把那些符合條件的列為True。
先用nba["Team"]選等於Boston Celtics,此時會出現一連串的True/False,代表資料是Boston Celtics就會顯示True,反之則False。這邊還沒篩選到資料,只有先把那些符合條件的列為True。接下來要nba["Team"]="Boston Celtics外面再加一個[]才能篩選出資料,等於告訴python說我要選出是True的資料。 同理,如果我要篩選30歲以上球員就在nba["age"]>30外加一個括弧變成nba[nba["age"]>30]。
單一條件式篩選等同於SQL語法: select * from nba where team="Boston Celtics" ,Phyton稍微麻煩了一些,還要包兩層括弧。

(2)多重條件篩選
分別看年齡和隊名還不夠,假設我想同時下年齡跟隊名呢? 例如說想看資料中隊名為Boston Celtics且年齡>25歲有幾筆,該如何下指令?
為了程式更簡潔易懂,設定兩個Flg,其中Flg1篩選隊名等於Boston Celtics、Flg2篩選年齡大於25歲,最後再用nba[flg1 & flg2] 將兩個條件共同篩選出來,若篩選條件更多,則可以同理類推製造flg3, flg4...完成多重條件篩選。

(3)單一條件多重內容物篩選
如果我想篩選不只是一個隊名呢? 假設想同時篩選3個隊名,按照上面的多重篩選方法可以創造3個flg,但同一個變數「隊名」要做三次,有沒有更快速的方法?
確實有。設定一個Flg先命名為Flg3,選取Team變數,再isin後面下想要的多個隊名,例如Toronto Raptors, Chicago Bulls, Brooklyn Nets等,如此一來就不需要創造3個Flg,可以在一次選取時就將三個條件篩選完畢。這個語法非常類似SQL中的select * from nba where team in ('Toronto Raptors', 'Chicago Bulls','Brooklyn Nets')。

篩選及刪除重複的值
資料分析時常常會遇到重複的值,譬如說要分析每隊年齡最大隊員之資料,┬但是在原始資料中每隊隊員有數十個人,該怎麼篩選出我們的目標值呢? 分為兩個步驟:
(1) 將原始資料排序:
重複的篩選依據什麼變數? 要篩選出每隊年齡最大之隊員,篩選的依據就是每隊需先依據年齡排序,用sort_values放入變數Age,其中ascending代表由小排到大,再這邊因為我們要篩選出年齡最大的隊員,由大排到小的話就下False,然後用inplace將原本的nba資料集取代。
用剛剛說明的篩選方式Boston Celtics隊的資料發現在資料集中每個隊員確實按照年齡由大排序到小了,這隊年齡最大的是29歲。
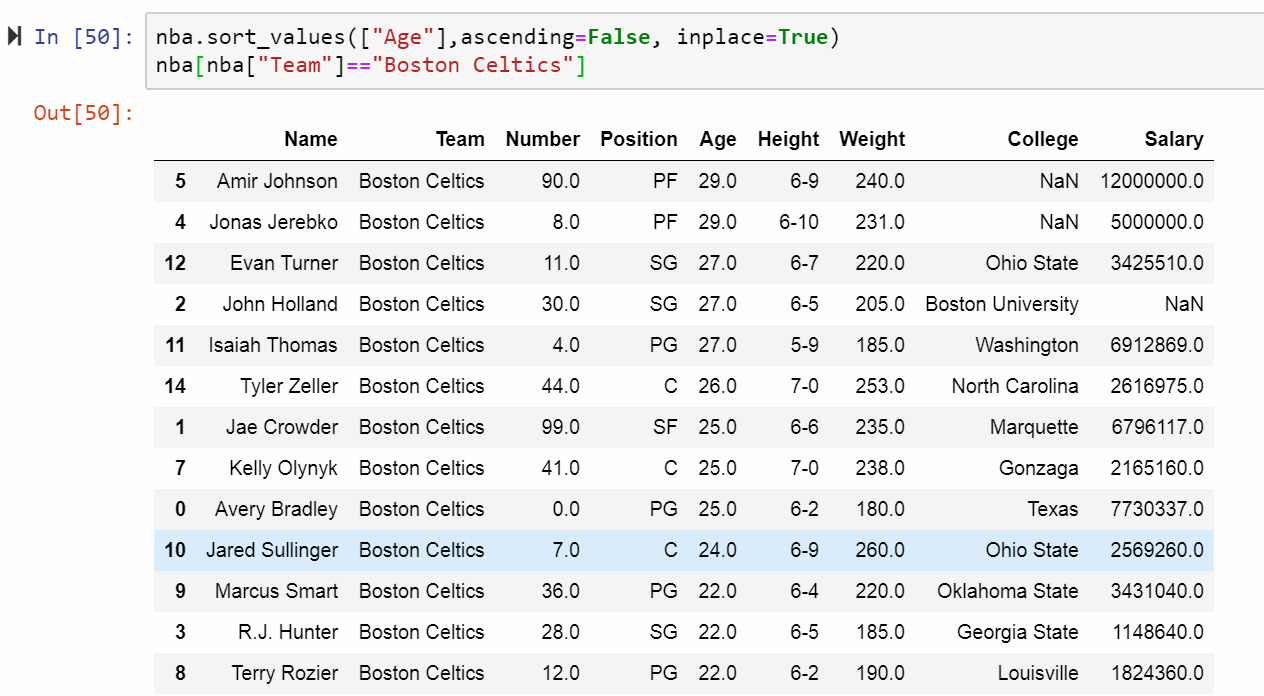
(2)除第一個值外,每隊篩除其他重複的值
drop_duplicateds這個method可以幫助我們刪除重複的值,惟在mothod中必須告訴pyton我是在每個不同隊名(Team)之下刪除,保留的是所有重複資料中的第一筆,因為剛剛依照大到小排序了資料,第一筆是我們要的年齡最大之隊員。

這時候將新的nba_mod資料集展開來看,可以看到大部分隊年齡大的隊員都有超過35歲,看來Boston Celtics算是年輕的隊囉!
在篩選重複值方面,若只是取一筆值SQL的distinct快許多,但若要依據年齡之類的排序,Phyton這邊處理倒是比較快速且輕鬆。

小小心得 & 參考資料分享
初學Python Pandas ,覺得很多邏輯和傳統資料庫語言SQL非常相似,學起來也似曾相似,Python Pandas可以快速載入EXCEL資料,以及網頁上操作簡潔的語言,似乎讓這套程式語言多了些靈活性! 篩選只是一開始入手的基本功,期待未來能夠學習更多Pandas相關運用囉!
Udemy線上課程: Data Analysis with Pandas and Python


{kind=link}
這篇文章寫得很淺顯易懂,謝謝您!
回覆刪除不客氣,謝謝您的鼓勵!
刪除